Underfitting and Overfitting
In the world of trading, the use of Machine Learning (ML) algorithms and models is becoming increasingly popular due to their ability to analyse large amounts of data to detect patterns and trends useful in predicting market movements. However, these models are not infallible and can run into two fundamental problems: underfitting and overfitting. While underfitting reflects the model’s inability to learn correctly from data, overfitting poses a more insidious threat, as it can create the illusion of effective strategies that fail when applied to new scenarios. For traders who rely on advanced technology, recognising and controlling overfitting is essential to avoid misleading decisions and financial losses. In this article, we will explore both concepts, focusing in particular on overfitting and how to mitigate its effects through simpler, generalisable validation techniques and models.
The Distinction

Overfitting
Overfitting, on the other hand, is the opposite problem. It occurs when a model is too complex and fits the training data too well, capturing not only real trends but also the noise and random anomalies within the data. In other words, the model becomes overly sensitive to variations in the training data, losing its ability to generalize.
While an overfit model may perform exceptionally well on the training data, its ability to predict new data (such as future market data) is poor. This can lead traders to overestimate the performance of their model during testing, only to make poor decisions when facing new market conditions.
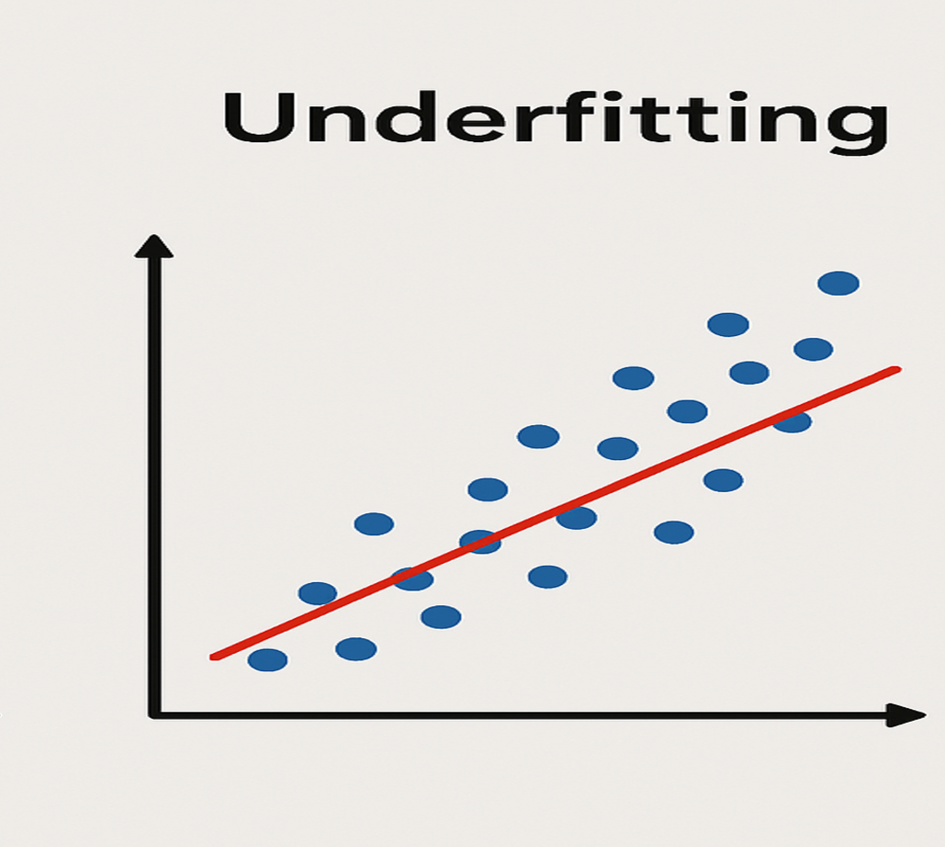
Underfitting
Underfitting occurs when a model is too simple and fails to capture meaningful relationships within the training data. Practically speaking, it’s like trying to draw a straight line to explain a highly complex and non-linear dataset. In trading, a model suffering from underfitting may fail to grasp relevant patterns influencing market prices, leading to generic and inaccurate predictions.
Common causes of underfitting include:
- Models that are too simple (e.g., using linear regression for highly non-linear data).
- An insufficient number of variables or features selected for the model.
- Inadequate training time.
The result of underfitting is generally low accuracy in both the training data and the test data. In trading, this can lead to ineffective strategies that fail to identify profit opportunities.
A Real Threat
In trading, overfitting is a concrete danger because ML models are trained on historical data, which may contain unique and unrepeatable fluctuations. An overfit model may detect false correlations or random patterns in the past that won’t repeat in the future. This issue becomes more relevant when using quantitative strategies, which rely on historical analyses to make future predictions.
Some reasons why overfitting is so common among traders include:
- Abundance of historical data: Financial markets provide vast amounts of data, but not all of it is truly relevant. Using too many parameters may lead to models that appear to work well on past data but fail to generalize on new data.
- Market noise: Financial markets are influenced by multiple external factors (news, investor sentiment, political changes), often random and unpredictable. Overly complex models may confuse these random events with real trends.
- Tendency for over-optimization: Traders often try to create models that maximize historical performance through techniques like hyperparameter optimization, which can lead to overfitting. By optimizing the model to fit past data too perfectly, it becomes ineffective in future market conditions.
How to Avoid Overfitting
For traders using ML models, avoiding overfitting is a priority. Here are some techniques that can help reduce this risk:
- Split data into training and test sets: It is essential to separate historical data into a training set and a test set, ensuring that the model is evaluated on unseen data during training.
- Cross-validation: Cross-validation, especially K-fold cross-validation, allows data to be divided into multiple subsets, training and testing the model on different parts of the data. This helps verify whether the model’s performance is consistent across various segments of the dataset.
- Model simplicity: It is better to use simpler models with fewer parameters, especially when limited historical data is available. Simpler models are less likely to capture noise.
- Regularization techniques: Methods like Lasso and Ridge regression add penalties to prevent the parameters from becoming too large, helping to reduce overfitting.
- Constant real-time performance monitoring: It is crucial to monitor the model’s performance on real data and update the model when necessary, avoiding reliance solely on historical data for future predictions.